This page introduces our paper in a graphical manner. The main goal is to explain the positioning and the content of the paper in an efficient way.
Fault tolerance
Fault Tolerance is a property of systems to maintain
their functionlity even when its components crash.
For neural networks, this means that the output is preserved even when some neurons crash
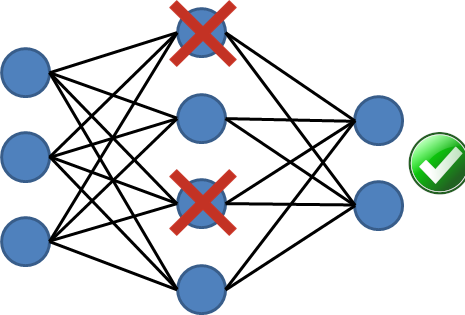
Fault tolerance in biological brains
Biological systems are known to be fault-tolerant
Fault tolerance in neuromorphic hardware
Neuromorphic hardware is an emergent computing paradigm
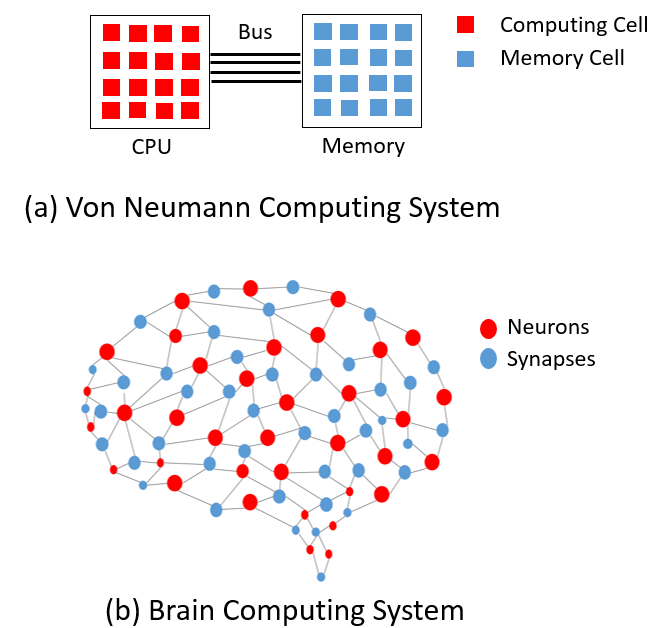
Research on fault tolerance
The problem of fault tolerance in neural networks consists of defending the performance of the network
against random crashes of individual neurons.
The problem was well-studied in the 90s
for small networks
Definitions
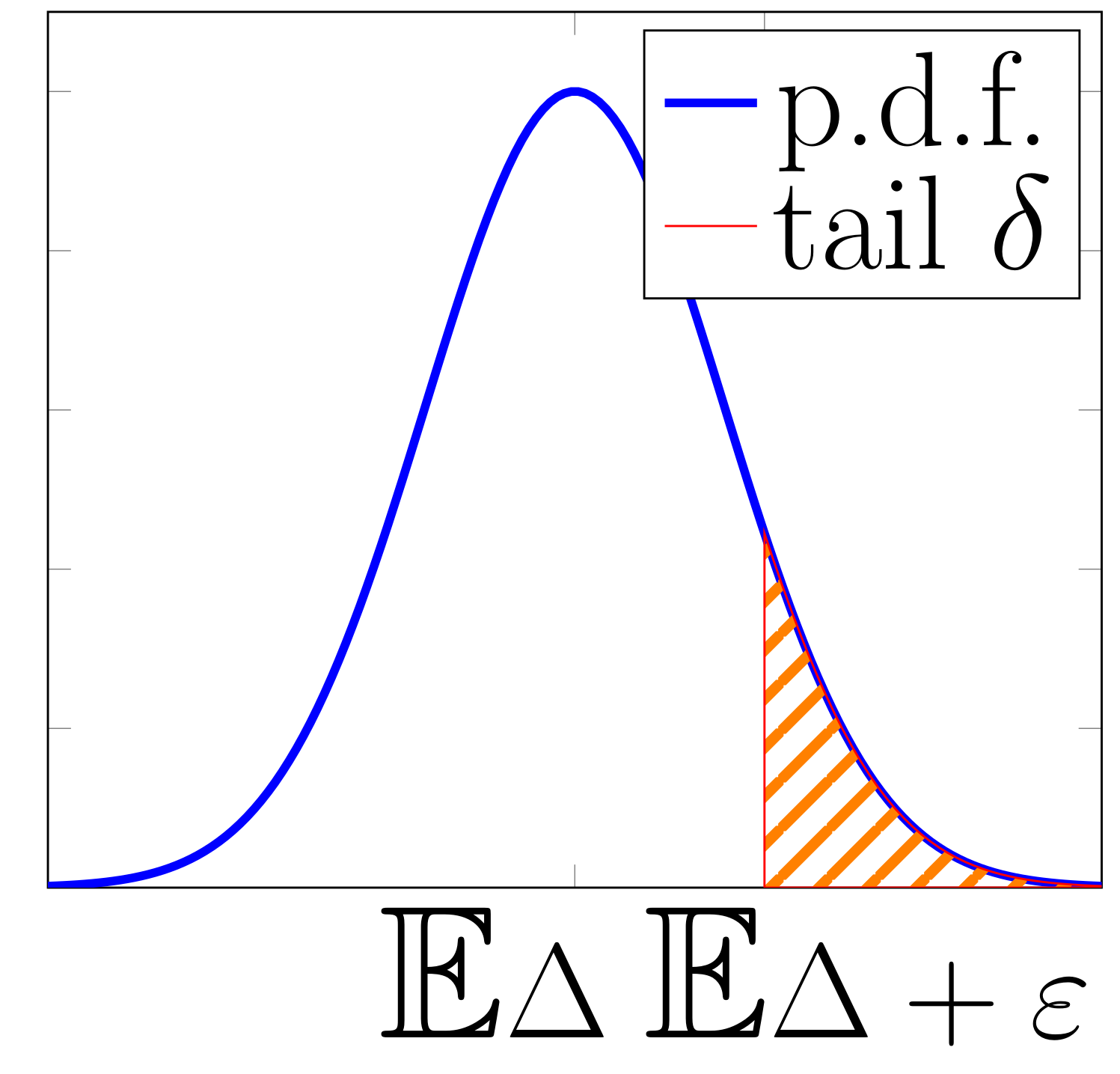
We quantify fault tolerance of a neural network as the error in the output: $$\Delta=\hat{y}-y$$ where $$\hat{y}$$ is the output of the network with crashed neurons, and $$y$$ is the original (correct) output. Our goal is to guarantee that the error $$\Delta$$ does not exceed $$\varepsilon$$ with a high probability $$1-\delta$$.
Fault Tolerance and Dropout
Our problem is mathematically similar to the theoretical study of Dropout
Fault Tolerance and Adversarial Examples
Our problem is also related to the phenomenon of Adversarial Examples
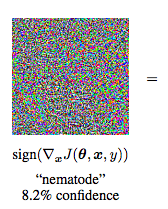
Main contribution
We derive a bound on $$\mathbb{E}\Delta$$ and